Java搜索技术深度解析与实战指南
一、搜索技术基础与核心算法
搜索功能作为现代应用的核心能力,其性能直接影响用户体验。Java作为企业级开发的首选语言,提供了丰富的搜索算法实现方案。让我们从最基础的实现开始,逐步深入高级应用场景。1.1...
Java搜索技术深度解析与实战指南
一、搜索技术基础与核心算法
搜索功能作为现代应用的核心能力,其性能直接影响用户体验。Java作为企业级开发的首选语言,提供了丰富的搜索算法实现方案。让我们从最基础的实现开始,逐步深入高级应用场景。
1.1 线性搜索:最直接的实现方式
public static int linearSearch(int[] arr, int target) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
时间复杂度O(n)的线性搜索虽然简单,但在小型数据集(<1000条)中表现优异,且无需数据预处理。实际开发中常用于未排序的集合快速查找。
1.2 二分搜索:有序数据的高效方案
public static int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) return mid;
if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1;
}
时间复杂度O(log n)的二分搜索要求数据预先排序,适合静态数据集。JDK中的Arrays.binarySearch()已提供优化实现。
二、高级搜索数据结构实战
2.1 哈希表搜索:O(1)时间复杂度的魔法
Java的HashMap通过哈希函数实现近乎瞬时的查找:
Map<String, Integer> productMap = new HashMap<>();
productMap.put("iPhone", 999);
productMap.put("Galaxy", 899);
Integer price = productMap.get("iPhone"); // 极速查找
2.2 Trie树:前缀搜索的理想选择
特别适合实现搜索提示和自动补全:
class TrieNode {
Map<Character, TrieNode> children = new HashMap<>();
boolean isEndOfWord;
}
public void insert(String word) {
TrieNode current = root;
for (char ch : word.toCharArray()) {
current = current.children.computeIfAbsent(ch, c -> new TrieNode());
}
current.isEndOfWord = true;
}
三、企业级搜索解决方案
3.1 Lucene核心原理剖析
Apache Lucene作为全文搜索引擎的基石,其核心由以下组件构成:
- 倒排索引(Inverted Index)
- 分词器(Analyzer)
- 评分机制(TF-IDF/BM25)
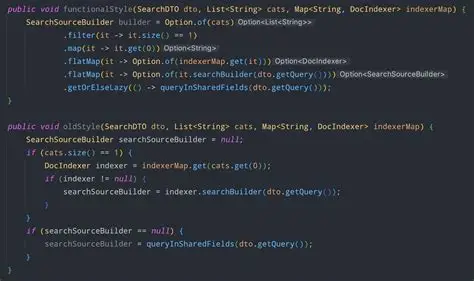
3.2 Elasticsearch整合实战
// 创建Elasticsearch客户端
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 构建搜索请求
SearchRequest request = new SearchRequest("products");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("name", "智能手机"));
request.source(sourceBuilder);
// 执行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
四、性能优化关键策略
- 索引优化:
- 合理设置分片数(建议每个分片30-50GB)
-
使用alias实现零停机索引切换
-
查询优化:
- 避免深分页(使用search_after替代from/size)
-
合理使用filter上下文(利用bitset缓存)
-
JVM调优:
- 设置合适的堆内存(不超过物理内存的50%)
- 使用G1垃圾回收器
五、未来趋势与新技术
- 向量搜索(Vector Search)在AI场景的应用
- 使用Apache Kafka实现近实时索引更新
- 云原生搜索架构设计
通过本文的系统学习,开发者可以掌握从基础算法到分布式搜索的全套技术栈。在实际项目中,应根据数据规模、实时性要求和业务特点选择合适的搜索方案。记住:没有最好的算法,只有最适合的场景解决方案。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。