在人工智能技术蓬勃发展的今天,语音转文字技术已成为提升人机交互效率的关键。本文将全面解析Java语音识别的技术实现路径,涵盖从基础原理到企业级应用的全套解决方案。一、语音转文字技术原理
语音识别(ASR)本质上是将连续的声波信号转化为离散文...
在人工智能技术蓬勃发展的今天,语音转文字技术已成为提升人机交互效率的关键。本文将全面解析Java语音识别的技术实现路径,涵盖从基础原理到企业级应用的全套解决方案。
一、语音转文字技术原理
语音识别(ASR)本质上是将连续的声波信号转化为离散文字的过程,主要包含以下技术环节:
1. 音频采集:通过麦克风获取16kHz以上采样率的PCM数据
2. 特征提取:MFCC(梅尔频率倒谱系数)特征分析
3. 声学建模:基于深度神经网络(DNN)的声学模型
4. 语言模型:N-gram或RNN语言模型
5. 解码器:维特比算法寻找最优路径

二、本地SDK实现方案
2.1 CMU Sphinx4
Configuration config = new Configuration();
config.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
config.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");
StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer(config);
recognizer.startRecognition(new FileInputStream("audio.wav"));
SpeechResult result;
while ((result = recognizer.getResult()) != null) {
System.out.println(result.getHypothesis());
}
优点:开源免费、支持离线
缺点:准确率约70%、仅支持英语
2.2 Microsoft Speech SDK
需安装Windows Desktop Runtime,支持中文识别:

SpeechConfig config = SpeechConfig.fromSubscription("KEY", "REGION");
config.setSpeechRecognitionLanguage("zh-CN");
AudioConfig audio = AudioConfig.fromWavFileInput("audio.wav");
SpeechRecognizer recognizer = new SpeechRecognizer(config, audio);
Future<SpeechRecognitionResult> task = recognizer.recognizeOnceAsync();
System.out.println(task.get().getText());
三、云服务API集成
3.1 阿里云智能语音交互
DefaultProfile profile = DefaultProfile.getProfile("cn-shanghai", "ak", "sk");
IAcsClient client = new DefaultAcsClient(profile);
SubmitTaskRequest request = new SubmitTaskRequest();
request.setAppKey("your_app_key");
request.setAudioUrl("https://your-audio.oss-cn-shanghai.aliyuncs.com/audio.wav");
request.setEnableWords(false);
SubmitTaskResponse response = client.getAcsResponse(request);
String taskId = response.getTaskId();
3.2 腾讯云语音识别
Credential cred = new Credential("secretId", "secretKey");
ClientProfile clientProfile = new ClientProfile();
ASRClient client = new ASRClient(cred, "ap-shanghai", clientProfile);
String payload = "{\"EngineModelType\":\"16k_zh\","
+ "\"VoiceFormat\":\"wav\","
+ "\"Url\":\"https://your-audio.cos.ap-shanghai.myqcloud.com/audio.wav\"}";
StringResponse resp = client.SentenceRecognition(payload);
System.out.println(resp.getData());
四、性能优化实践
- 音频预处理:
- 使用FFmpeg统一转为16kHz单声道
- 音量归一化(-20dBFS)
-
降噪处理(noise profile)
-
并发处理:
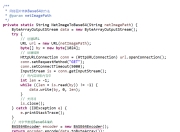
ExecutorService pool = Executors.newFixedThreadPool(8);
List<Future<String>> results = new ArrayList<>();
for(File audio : audioFiles) {
results.add(pool.submit(() -> {
return recognize(audio);
}));
}
- 缓存机制:
- Redis缓存识别结果
- Memcached存储语音特征
五、企业级方案选型建议
| 方案类型 | 识别准确率 | 响应延迟 | 成本 | 适用场景 |
|---|---|---|---|---|
| 本地开源SDK | 60-75% | <1s | 免费 | 离线简单场景 |
| 商业SDK | 85-92% | <2s | 授权费 | 专业桌面应用 |
| 云端通用API | 90-95% | 2-5s | 按量计费 | 移动互联网应用 |
| 定制化引擎 | >96% | <1s | 高额定制费 | 金融/医疗等专业领域 |
六、SpringBoot整合实战
@RestController
public class AsrController {
@PostMapping("/recognize")
public String recognize(@RequestParam MultipartFile file) {
String url = ossService.upload(file);
AsrTask task = asrService.submitTask(url);
return Result.success(task.getTaskId());
}
@GetMapping("/result/{taskId}")
public String getResult(@PathVariable String taskId) {
return asrService.getResult(taskId);
}
}
通过本文的实践演示,开发者可以快速构建适合自身业务场景的Java语音识别系统。建议初创团队优先采用云服务API,待业务量增长后再考虑混合云或本地化部署方案。最新技术趋势显示,端云结合的语音识别架构将成为未来主流发展方向。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。